Learn AI Game Playing Algorithm Part I — Game Basics

Game AI has always been a popular field with many impressive achievements. Next, I will start writing a series of three posts, talking about some fundamental and important game-playing algorithms.
- Part I — Game Basics
- Part II — Monte Carlo Tree Search (MCTS)
- Part III — Counterfactual Regret Minimization (CFR)
In Part I, which is this post, I will explain some of the prior knowledge for game AI. Specifically, I will introduce (1) How to represent a game using computational logical structure (2) Different types of games (3) Three concepts that proven to be important for designing game-solving algorithms.
In Part II, I will present Monte Carlo Tree Search [1,3], a building block algorithm for solving perfect information games like chess and go [2]. In Part III, I will introduce Counterfactual Regret Minimization [6], an effective method of solving imperfect information games like poker [19].
I want to note in advance that I will try to make the concepts more understandable and intuitive rather than striving for rigor. The mathematical language is not standard enough in this series, and please excuse me for this.
Game Representation
The world is full of games, but to solve them with computers, we first need to represent them with logical structures.
Game Tree
The first essential structure is the game tree, which represents the process of a game with a tree whose nodes and edges represents states and actions, as explained below in a game tree of Tic Tac Toe with annotations:
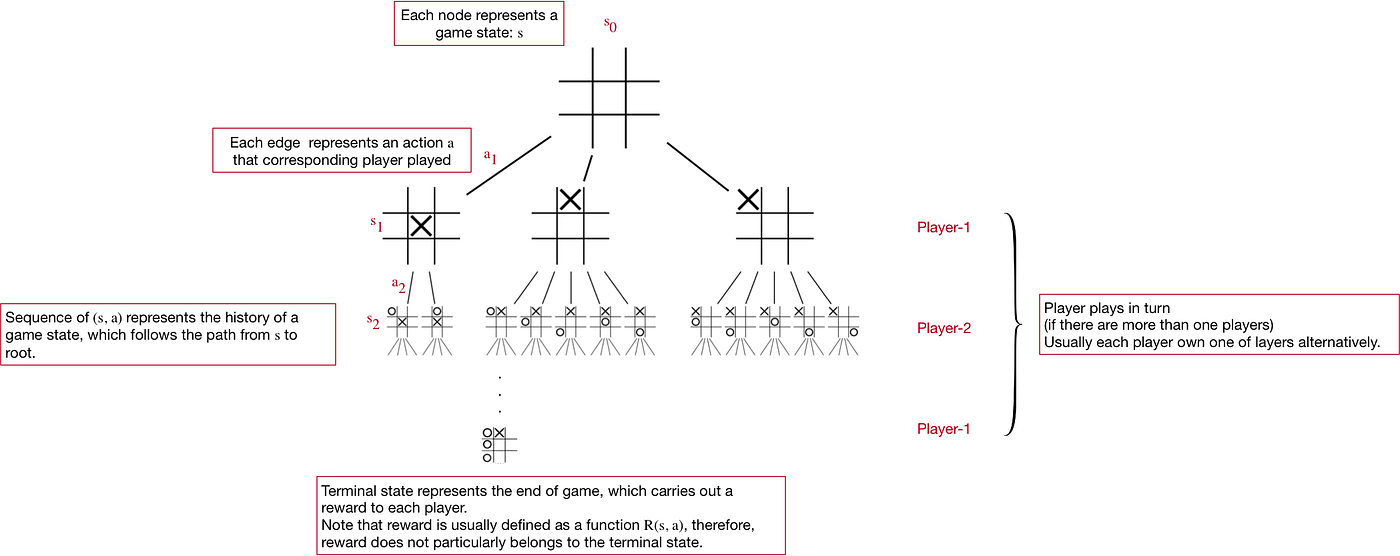
Though the game tree looks simple and straightforward, it can model many vital components of a game:
- State
- Player
- Action; we can define the set of available actions under state s as A(s).
- Reward R(s, a)
- Turn
- Terminal state (end of the game)
- Decision Sequence (sᵢ, aᵢ)
- Strategy π(a|s), which is a distribution of actions given state. We also use σ to denote strategy.
- Utility function u(s) or u(s, a), which describes the usefulness of state s to a player and can be defined individually.
The game tree grants us a powerful mental and programmatical model to represent the playing processes of a wide variety of games.
In fact, game tree is a simplified and perceptual definition for the extensive-form game [7]. Many important games solving techniques like MCTS, Minimax Search [5], Counterfactual Regret Minimization [6] can be generalized as a game tree construction, traversal, and node value update process. In my opinion, I even think the game tree is one of the most important concepts, if not the most.
Game Matrix
Game matrix is another way to represent games, which corresponds to the normal-form game [9], as explained below with a 2x2 board of Tic Tac Toe:
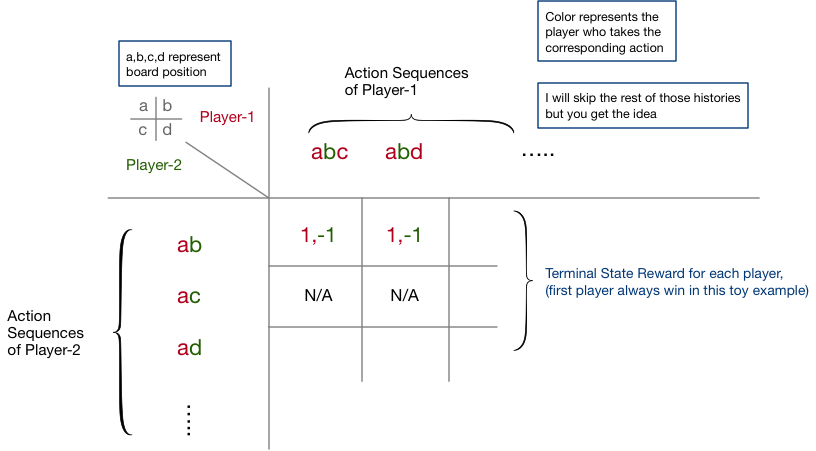
As we can see, a game matrix assumes all players act simultaneously. Therefore, to model sequential decisions, the matrix has to expand the game tree exhaustively to cover all possible histories, as shown in the figure above, which makes this representation unscalable for sequential decision games.
However, the game matrix also has its advantages; there are proven methods to find a Nash equilibrium of a game matrix [8]. Nash equilibrium turns out to be extremely useful for understanding the game nature and designing game playing strategies. We will come back to the Nash equilibrium in the later section.
Game Categorization
After we know how to represent games, we can step further to categorize them. Here I present three major categories:
Perfect Information Game
- Every player knows the full decision sequence of the game [10].
- Examples are Chess, Go, Soduku, Tic Tac Toe, where the game board is the whole game state and can always be observed by anyone, and every player action is public.

Note that there is another concept called Perfect Recall, which means every player can memorize every event during the game process, which is irrelevant to the game category.
Imperfect Information Game
(Opposite of the former)
- Examples are Poker, Mahjong, where you cannot know the opponents’ card stacks.

- In a game with imperfect information, players cannot observe the actual game state s, which means we cannot use π(a|s) to represent strategy. Therefore, we introduce the definition of Information Set [23]. We will come back to this topic in Part III of this series.
Incomplete Information Game
- Players do not have the common knowledge of the game being played, e.g. objectives, rules, and even players.
- Take an example from [11]: Two bidders bid for one item, and the auction is sold to the highest price. However, each player only knows the item’s value for himself, but not the rival’s valuation (lack of common knowledge).
- For a complete information game, we usually assume every player knows the game’s rules and every player’s objective. Therefore, the incomplete information game is indeed more generalized and realistic. Note that the game tree can represent incomplete information by introducing “chance players” [7].
Three Important Concepts for Solving Games
We have learned about the logical structure and categories of games in the sections above. Here we look at three concepts that are behind many game-playing algorithms. In practice, they are often used in conjunction with each other. Understanding them is very helpful.
Idea-1 Bellman Equation
Bellman equation is the basis for most methods of reinforcement learning. However, surprisingly, it comes from a straightforward definition of the state utility, also known as value function V:
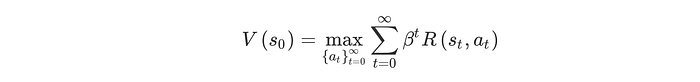
where β is a temporal discount factor.
This definition says the value (or utility) of a state s is the maximum reward of every decision sequence from s. As we care more about the present, we discount the reward in time, which feels very logical and natural.
The fantastic thing is that the above definition itself contains an optimal substructure [14], so we can write it in a recursive form, which is the Bellman equation:
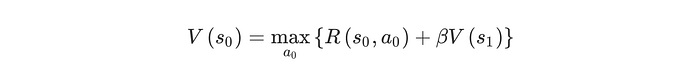
Bellman equation is a powerful tool for reinforcement learning, upon which we can design various iterative optimization algorithms. And we can use these optimization algorithms to calculate value function V(s), strategy π(a|s) and even Q function Q(a, s) [15], according to which computers can play games.
Idea-2 Nash Equilibrium
Nash equilibrium (NE) is one of the most essential principles, if not the most important one, for designing multi-player game strategies, which closely relates to defining a good strategy.
It says for every finite game, there exists a Nash equilibrium strategy (NES) for all players, under which no player can have anything to gain by only changing their strategy. This state is called the Nash equilibrium.
In a two player zero sum game, the mathematical form for describing the Nash Equilibrium is:
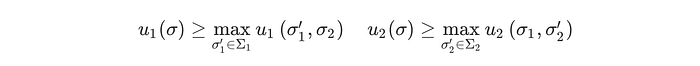
Moreover, the minimax theorem [16] says that NES in such a game is identical to the minimax search strategy, which may not seem evident initially, but [17] explains this quite clearly.
In real world multi-player games, there is hardly any perfect strategy, because theoretically playing with different players requires that the strategy be adjusted. However, we tend to think that strategies are good if they can maximize personal gain (maximize) and protect ourselves as much as possible from the strong players (minimize), just as the NES does.
Therefore, intuitively, a Nash equilibrium strategy is a conservative but good strategy, though not optimal, like in prisoner dilemma [18], it works well in practice. Many successful works on solving imperfect information games are based on the idea of optimizing strategy to approximate Nash equilibrium state [19,20,21].
Idea-3 Simulation
Compared to the first two concepts, simulation is much simpler. It comes from the basic idea that if we use our computer strategy to play with itself and build game trees, then from this tree we can extract a lot of knowledge and thus discover much stronger strategies.
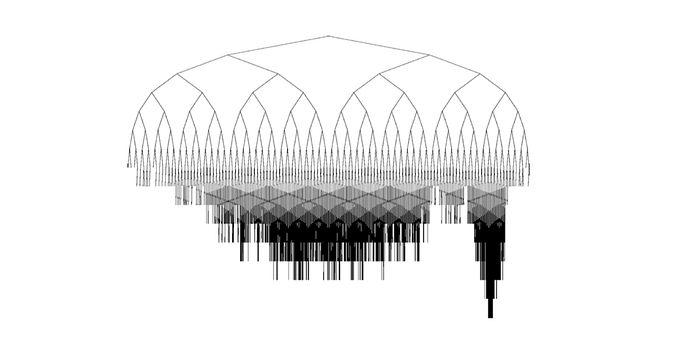
This is very similar to the way human reasons. By reasoning, we can discover useful and non-obvious knowledge and can even use the new knowledge as a basis for further learning and planning.
Summary
In this post, I talk about game representation, categorization, and three game-solving concepts crucial for further learning of more algorithms. I hope you find it useful. In the next post, I will explain Monte Carlo Tree Search and how it solves perfect information games like chess.
Reference
[1]: Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search https://hal.inria.fr/inria-00116992/document
[2]: Mastering the game of Go with deep neural networks and tree search https://www.nature.com/articles/nature16961
[3]: Improved Monte-Carlo Search http://old.sztaki.hu/~szcsaba/papers/cg06-ext.pdf
[4]: By Traced by User:Stannered, original by en:User:Gdr — Traced from en:Image:Tic-tac-toe-game-tree.png, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=1877696
[5]: Minimax https://en.wikipedia.org/wiki/Minimax
[6]: Regret Minimization in Games with Incomplete Information https://papers.nips.cc/paper/2007/file/08d98638c6fcd194a4b1e6992063e944-Paper.pdf
[7]: Extensive-form game https://en.wikipedia.org/wiki/Extensive-form_game
[8]: Nash equilibria in a payoff matrix https://en.wikipedia.org/wiki/Nash_equilibrium#Nash_equilibria_in_a_payoff_matrix
[9]: Normal-form game https://en.wikipedia.org/wiki/Normal-form_game
[10]: Perfect information https://en.wikipedia.org/wiki/Perfect_information
[11]: Games of Incomplete Information http://web.stanford.edu/~jdlevin/Econ%20203/Bayesian.pdf
[12]: By Req: Science Law Chess — Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=37494366
[13]: By Thomas van de Weerd from Utrecht, The Netherlands — Pokeravond, CC BY 2.0, https://commons.wikimedia.org/w/index.php?curid=2106370
[14]: Bellman’s principle of optimality https://en.wikipedia.org/wiki/Bellman_equation#Bellman's_principle_of_optimality
[15]: Q-learning https://en.wikipedia.org/wiki/Q-learning
[16]: Minimax theorem https://en.wikipedia.org/wiki/Minimax_theorem
[17]: Ziv (https://math.stackexchange.com/users/7261/ziv), Difference between Minimax theorem and Nash Equilibrium existence, URL (version: 2011–02–19): https://math.stackexchange.com/q/22824
[18]: Prisoner’s dilemma https://en.wikipedia.org/wiki/Prisoner%27s_dilemma
[19]: Superhuman AI for multi-player poker https://science.sciencemag.org/content/365/6456/885
[20] Regret Minimization in Games with Incomplete Information https://papers.nips.cc/paper/2007/file/08d98638c6fcd194a4b1e6992063e944-Paper.pdf
[21] Monte Carlo Sampling for Regret Minimization (MCCFR) in Extensive Games http://mlanctot.info/files/papers/nips09mccfr.pdf
[22] A Survey of Monte Carlo Tree Search Methods http://ccg.doc.gold.ac.uk/ccg_old/papers/browne_tciaig12_1.pdf
[23] Information set (game theory) https://en.wikipedia.org/wiki/Information_set_(game_theory)
[24] Robots won’t just take jobs, they’ll create them — TechCrunch
